How to Track AI Cost Per Customer in a Multi-Tenant SaaS Application
A technical blueprint for building robust per-tenant cost attribution and streaming ledger systems.

Most AI-powered SaaS companies know exactly how much they spend on LLM providers each month. What few can answer is a much more critical economic question: Which specific customers are generating that bill, and are they still profitable?
In traditional SaaS, compute and database costs scale minimally with user activity, allowing for simple flat-rate pricing. In AI products, usage-based infrastructure costs are significant and variable. A power user on a flat-rate tier can run up hundreds of dollars in monthly model costs, quietly turning their account into a net-loss.
To protect your margins, you must connect user identity in your application database to raw token usage at the provider level. This requires a dedicated cost-ledger architecture.
The $99 Customer Problem
Consider two enterprise customers on a standard $99/month subscription tier:
| Customer | Monthly Revenue | Model Requests | Avg. Tokens per Request | Total LLM Cost | Gross Profit |
|---|---|---|---|---|---|
| Customer A | $99.00 | 150 | 2,000 | $0.90 | +$98.10 |
| Customer B | $99.00 | 25,000 | 15,000 | $112.50 | -$13.50 |
Both users appear identical in your billing system, but Customer B is active enough to wipe out all profit from Customer A.
Without customer-level cost attribution, your gross margins become a guessing game. You cannot make informed decisions about product pricing, feature limits, or sales discounts because you lack visibility into the underlying cost of goods sold (COGS).
Why Provider Dashboards Fail at Multi-Tenancy
Standard dashboards from OpenAI, Anthropic, or Google are built for aggregate billing, not multi-tenancy. They provide insights into total token usage, model splits, and overall cost, but they operate completely outside your application context.
To a provider like OpenAI, your application is a single client making millions of API calls using a shared key. The provider has no concept of your tenant_id, your user accounts, or which specific product features triggered a call.
To bridge this gap, your application must intercept every outbound request, tag it with business metadata, and log the resulting token usage in a local database ledger.
Designing an AI Cost Ledger Architecture
A robust cost attribution system uses an interceptor pattern. Every request to an LLM must pass through a middleware proxy that injects user metadata, forwards the request to the provider, captures the usage payload from the response, and writes the record to an analytical database.
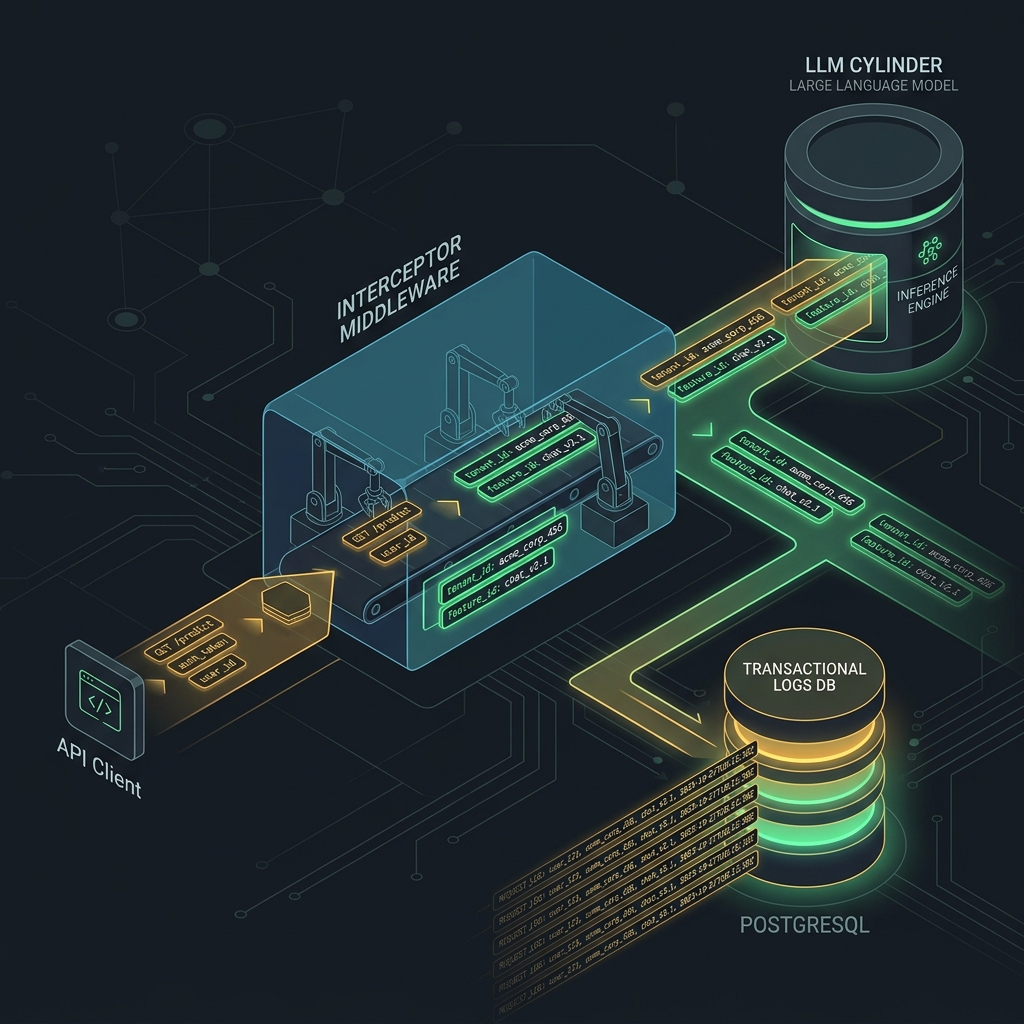
This architecture consists of four primary stages:
- Metadata Tagging: Your application attaches
tenant_idandfeature_idheaders to the request. - Proxy / Interceptor: A gateway reads the headers, strips them before sending the request to the LLM provider, and logs the transaction.
- Usage Parsing: The proxy extracts the input and output token counts from the provider's response.
- Ledger Storage: Usage metrics are written to a time-series or append-only ledger database to build a historical cost record.
Implementation: Middleware Cost Interception
Here is a simplified example of how you can implement cost interception inside your application's API routing layer:
// Intercepting and logging LLM usage metrics
export async function routeAIRequest(req: Request) {
const tenantId = req.headers.get("x-tenant-id");
const featureId = req.headers.get("x-feature-id") || "general";
const model = "gpt-4o";
// 1. Forward request to LLM provider
const response = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: {
"Authorization": `Bearer ${process.env.OPENAI_API_KEY}`,
"Content-Type": "application/json"
},
body: req.body
});
const data = await response.json();
// 2. Extract token usage from response payload
const inputTokens = data.usage?.prompt_tokens || 0;
const outputTokens = data.usage?.completion_tokens || 0;
// 3. Calculate cost based on current model rates
const promptRate = 0.005 / 1000; // $5.00 per million tokens
const completionRate = 0.015 / 1000; // $15.00 per million tokens
const calculatedCost = (inputTokens * promptRate) + (outputTokens * completionRate);
// 4. Record to the local ledger database
await writeToLedger({
tenantId,
featureId,
model,
inputTokens,
outputTokens,
costUsd: calculatedCost,
timestamp: new Date()
});
return new Response(JSON.stringify(data));
}
The Complexity of Multi-Provider & Agent Accounting
While a basic wrapper is simple to set up for a single provider, production applications quickly run into architectural challenges:
1. Multi-Provider Normalization
Most production systems route traffic across a blend of providers—using Claude for reasoning, GPT-4o for structured output, and Llama 3 for translation.

Each provider returns token usage in different formats, supports different headers, and updates their pricing schemas independently. Your ledger must parse and normalize these formats into a unified cost record in real time.
2. Parent-Child Tracking for Agentic Workflows
Modern AI systems are shifting from single prompt-responses to agents. A single user action might trigger an agent that spawns five tool runs, three vector database searches, and four LLM calls in a loop.
To track this accurately, you must pass a parent trace_id down through the execution chain. This allows you to aggregate dozens of child tool executions under the parent tenant request, giving you a true representation of user-triggered costs.
3. Token Counting in Streams
To maintain low latency, production AI features almost always stream responses. Since token metrics are only returned at the very end of the stream, your middleware must reconstruct the stream chunk-by-chunk, use client-side tokenizers (like tiktoken) to calculate usage, or capture final provider stats once the connection finishes.
The Shift to Runtime Enforcement
Attributing costs is the first step toward unit economics sanity. The next step is control.
Dashboards are post-mortem; they tell you when a tenant has already run up a $5,000 bill. True cost control requires setting up runtime budget enforcement at the gateway level. If a customer's monthly budget is exhausted, your gateway must automatically reject the request, throttle the connection, or route them to a cheaper fallback model in real time.
Where Synvolv Fits
Building and maintaining this infrastructure internally—from token calculators to streaming interceptors and provider sync systems—diverts valuable engineering cycles from your core product.
Synvolv is a plug-and-play AI gateway that automatically handles per-tenant cost tracking, token normalization, multi-model routing, and real-time budget enforcement. By changing your API base URL to Synvolv, you gain full unit economics visibility and margin control instantly, without adding latency to your applications.
Ready to take control of your AI costs?
See how Synvolv gives you per-customer cost attribution and runtime budget enforcement.